File Pre-Processing
Introduction
Pre-Processing is used to alter a fixed-length files to help the Paygate importer understand and read the file.
Pre-processing consists of a number of user defined rules that alter the incoming file. For example a rule might chop off the first 100 characters of a file or pad each line to a set length. The now ‘fixed’ file can now more easily be read into Paygate using the standard fixed length importer.
When pre-Processing takes place
Pre-processing takes place after the file cleaning process.
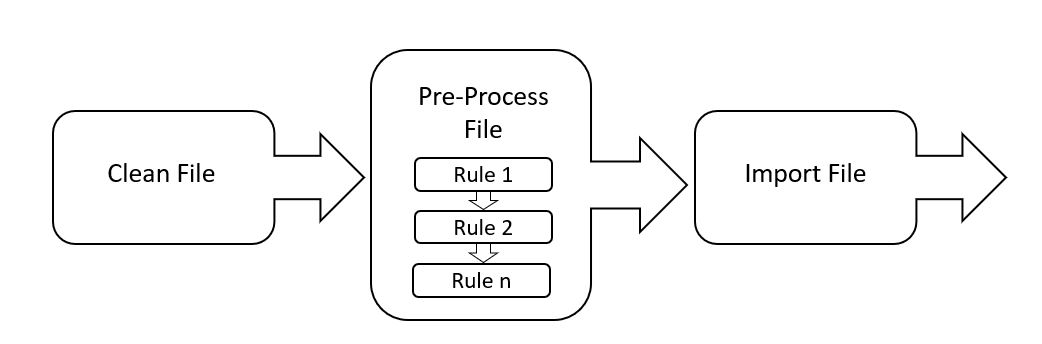
The image below shows the path that the importer takes when importing a fixed length file.
Rules are carried out in order, one at a time. After each rule is run the file is re-saved.
At the start of running each rule the file is re-loaded so that the re-loaded file contains all of the changes that the previous rules made.
Using the Pre-Processor
The Pre-processor can be found as part of the Fixed-Length Importer configuration. By default pre-processing is disabled. You enable it by clicking the ‘Enable Pre-processing’ switch.
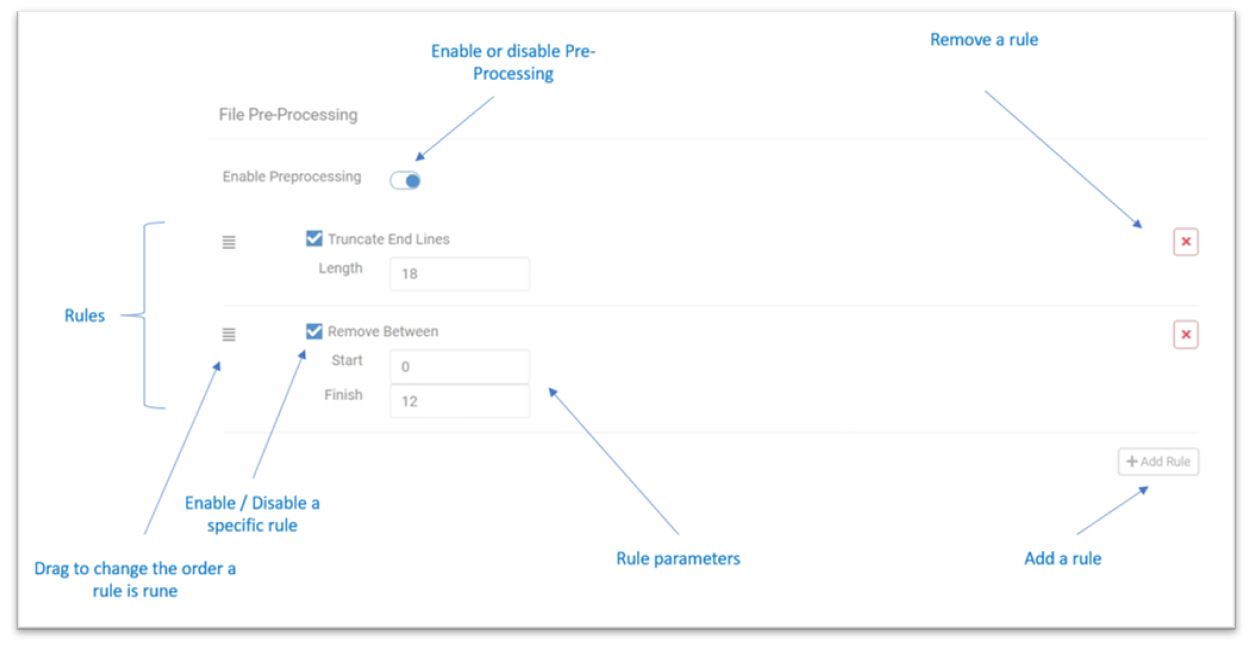
Click ‘Add Rule’ to display the rule picker. Select a rule from the drop-down box to add the rule to the rule list. You can add as many rules as you like and the same rule can be added more than once. As previously mentioned, rules are run in order - top to bottom. Therefore the ordering of the rules is important. The ordering of rules can be changed if required using the grab handles.
Pre-Processing Rules
Replace Text
Replaces all instances of a matching fragment of text within the entire file.
Parameters
Old The text within the file that will be replaced. Note: text is case sensitive.
New The text that will be used as a replacement.
Remove First Characters
Removes a set number of characters from the beginning of a file.
Parameters
Number The number of characters to remove from the beginning of the file.
Remove Last Characters
Removes a set number of characters from the end of a file.
Parameters
Number The number of characters to remove from the end of the file.
Remove Between
Removes a section of text between two positions within the file.
Parameters
Start The (zero based) location within the document that marks the start of text that will be removed from the file.
Finish The (zero based) location within the document that marks the end of text that will be removed from the file.
For example: A Start value of 5 and a Finish value of 10 will remove 5 characters from the file from positions 5 to 10.
Slice File
Slices a file with no row delimiters into equal length rows.
Parameters
Length The length of each slice.
For example. Lets say your file contains the following text: ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZ
Slicing this text using a value of 26 will result in the following: ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ
At the end of the slice process the long length of text is split into rows of length 26 characters. Each row is terminated with the standard Windows row termination of CR LF (carriage Return, Line Feed)
Remove Line if Starts With
If the file is split into separate rows, this rule can selectively remove entire rows if the row starts with a particular text value.
Parameters
Text The text to use to determine if the row should be removed.
For example: let’s say we had a file that contains the following:
ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ XXXDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ XXXDEFGHIJKLMNOPQRSTUVWXYZ
If we used a text value of XXX, the third and fifth rows would be removed from the file leaving:
ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ
Remove Line if Contains
If the file is split into separate rows, this rule can selectively remove entire rows if the row contains a particular text value.
Parameters
Text The text to use to determine if the row should be removed.
For example: let’s say we had a file that contains the following:
ABCDEFGHIJKLMNXXXRSTUVWXYZ ABCDEFGHIXXLXNOPQRSTUVWXYZ ABCDEXXXXXXLMNOPQRSTUVWXYZ ABCDEFGHIJKLMNXXXRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ
If we used a text value of XXX, the first, third and fourth rows would be removed from the file leaving:
ABCDEFGHIXXLXNOPQRSTUVWXYZ ABCDEFGHIJKLMNOPQRSTUVWXYZ
Note the second row remains because although it contains three X’s, they do not exactly match the text XXX.
Insert at Position
Inserts a block of text into a specific position within the file
Parameters
Text The text to be inserted into the file.
Position The (zero based) position within the file where the text will be inserted.
For example: Say you have a file containing the following:
ABCDEFGHIXXLXNOPQRSTUVWXYZ
Being zero based, we start counting from the start at position zero. B is at position 1, C at 2, etc.
We use the text ‘XXXX’ and we insert this at position 6. The file will look as follows:
ABCDEFXXXXGHIXXLXNOPQRSTUVWXYZ
Note the number of characters has increased because the text was inserted but did not replace any existing text.
Pad Start of Lines
In a file that is split into delimited rows, this rule pads each row so that each row is at least a certain length.
Parameters
Pad Char The character that will be used to pad the row. The default is a whitespace (ASCII 32).
Length The length of the line each row will be padded out to. Note: Lines that are longer than the length will be ignored.
For Example: Say we have a file that contains the following:
ABCDEFGHIXXLXNOPQRSTUVWXYZ
FGHIXXLXNOPQRSTUVWXYZ
ABCDEFGHIXXLXNOPQRSTUVWXYZ
CDEFGHIXXLXNOPQRSTUVWXYZ
HIXXLXNOPQRSTUVWXYZ
We use the default pad character and a length of 26. The file will now look like this:
ABCDEFGHIXXLXNOPQRSTUVWXYZ
FGHIXXLXNOPQRSTUVWXYZ
ABCDEFGHIXXLXNOPQRSTUVWXYZ
CDEFGHIXXLXNOPQRSTUVWXYZ
HIXXLXNOPQRSTUVWXYZ
Pad End of Lines
In a file that is split into delimited rows, this rule pads each row so that each row is at least a certain length.
Parameters
Pad Char The character that will be used to pad the row. The default is a whitespace (ASCII 32).
Length The length of the line each row will be padded out to. Note: Lines that are longer than the length will be ignored.
For Example: Say we have a file that contains the following:
ABCDEFGHIXXLXNOPQRSTUVWXYZ FGHIXXLXNOPQRSTUVWXYZ ABCDEFGHIXXLXNOPQRSTUVWXYZ CDEFGHIXXLXNOPQRSTUVWXYZ HIXXLXNOPQRSTUVWXYZ
We use the pad character * and a length of 26. The file will now look like this:
ABCDEFGHIXXLXNOPQRSTUVWXYZ FGHIXXLXNOPQRSTUVWXYZ***** ABCDEFGHIXXLXNOPQRSTUVWXYZ CDEFGHIXXLXNOPQRSTUVWXYZ** HIXXLXNOPQRSTUVWXYZ*******
Truncate Start of Lines
In a file that is split into delimited rows, this rule truncates each row so that each row has a maximum length
Parameters
Length The length of the line each row will be truncated to. Note: Lines that are shorter than the length will be ignored.
For Example: Say we have a file that contains the following:
ABCDEFGHIXXLXNOPQRSTUVWXYZ FGHIXXLXNOPQRSTUVWXYZ ABCDEFGHIXXLXNOPQRSTUVWXYZ CDEFGHI HIXXLXNOPQRSTUVWXYZ
We use a length of 12. The file will now look like this:
OPQRSTUVWXYZ OPQRSTUVWXYZ OPQRSTUVWXYZ CDEFGHI OPQRSTUVWXYZ
Truncate End of Lines
In a file that is split into delimited rows, this rule truncates each row so that each row has a maximum length
Parameters
Length The length of the line each row will be truncated to. Note: Lines that are shorter than the length will be ignored.
For Example: Say we have a file that contains the following:
ABCDEFGHIXXLXNOPQRSTUVWXYZ FGHIXXLXNOPQRSTUVWXYZ ABCDEFGHIXXLXNOPQRSTUVWXYZ CDEFGHI HIXXLXNOPQRSTUVWXYZ
We use a length of 12. The file will now look like this:
ABCDEFGHIXXL FGHIXXLXNOPQ ABCDEFGHIXXL CDEFGHI HIXXLXNOPQRS